반응형
안녕하세요 오늘은 네이버 증권에서
상한가를 크롤링해보려고 합니다.
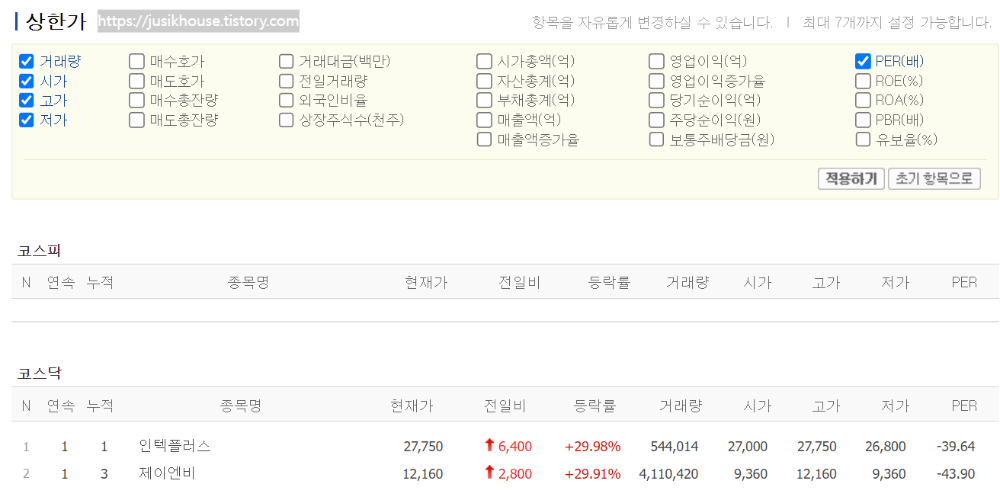
상한가와 코스피, 코스닥 3개이며 체크와 적용하기를 통해 리스트를 변경할 수 있습니다.
저는 여기서 PER(배),고가, 저가를 체크 해제하고 진행해보겠습니다.
우선 해당되는 체크박스 3개와 적용하기의 full xpath를 긁어옵니다.
#PER(배)
/html/body/div[3]/div[2]/div[2]/div[1]/div[2]/form/div/div/table/tbody/tr[1]/td[6]/input
#고가
/html/body/div[3]/div[2]/div[2]/div[1]/div[2]/form/div/div/table/tbody/tr[3]/td[1]/input
#저가
/html/body/div[3]/div[2]/div[2]/div[1]/div[2]/form/div/div/table/tbody/tr[4]/td[1]/input
#적용하기
/html/body/div[3]/div[2]/div[2]/div[1]/div[2]/form/div/div/div/a[1]/img
크롬에서 체크박스에 오른쪽 클릭 후 검사를 누르시면 옆에 창이 하나 뜨는데,
새로 뜬 창에서 표시되는 부분에 오른쪽 클릭 후 COPY에서 copy full xpath를 누르시면 됩니다.
도구 가져오기
우선은 셀레리움에서 웹 드라이버와, 드라이버에서 옵션을 추가로 가져옵니다.
또한 딜레이를 위해 타임도 같이 가져옵니다.
#셀레니움에서 왭 드라이버사용하기
from selenium import webdriver
#문서(HTML) 내 요소를 찾기 위해 import
from selenium.webdriver.common.by import By
#딜레이를 위한 time
import time
웹 실행하기
크롬을 실행하고 링크는 우선 임의로 upper_url에 넣어줍니다.
또한 2초간 대기시킵니다.
time.sleep(float 초)입니다 0.1초도 가능하며, 입력 시간만큼 프로그램이 멈춥니다.
이때 import random을 같이 사용하는 경우도 많습니다.
time.sleep(random.uniform(0.1,5))
위처럼 입력하면 동일하게 float 데이터를 입력받기에 0.1~5초 사이의 랜덤값을 넣어주게 됩니다.
#upper_url에 링크를 넣어주고
upper_url = "https://finance.naver.com/sise/sise_upper.naver"
#위 두 조건으로 실행
wd.get(upper_url)
#실행 후 2초 딜레이
time.sleep(2)
그 후 모든 문서를 합치면
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
wd = webdriver.Chrome()
upper_url = "https://finance.naver.com/sise/sise_upper.naver"
wd.get(upper_url)
time.sleep(2)
버튼 클릭 문구를 넣어야 하는데 너무 길어서 고민이 됩니다.
반응형
wd.find_element(By.XPATH, '/html/body/div[3]/div[2]/div[2]/div[1]/div[2]/form/div/div/table/tbody/tr[1]/td[6]/input').click()
time.sleep(0.5)
위 문장은 한 줄입니다.
#1
wd.find_element(By.XPATH,' 위에서 copy 한 xpath').click()
#2
btn = wd.find_element(By.XPATH,' 위에서 copy 한 xpath').click()
btn.click()
하면 됩니다.
창이 아마 선택 후 바로 꺼지게 될 텐데..
밑에 time.sleep을 하게 되면 좀 길게 보실 수 있습니다.
다음엔 리스트를 긁어 오는 것과 엑셀로 저장하는 것을 해 보겠습니다.
반응형
'일상 > 웹 크롤링 연습' 카테고리의 다른 글
| 네이버 증권에서 상한가 크롤링하기 (2탄) (0) | 2024.07.02 |
|---|---|
| 크롤링 연습 (0) | 2024.06.29 |
